

Would you fly in an aircraft that wasn’t tested? Get behind the wheel of a car whose model hadn’t been crash-tested? What about using a distributed database for storing your mission critical data that hadn’t been tested and gone through quality assurance?
I’d happily wager that if you are a database developer, then anyone that makes use of your database - whether that be directly (developer or database administrator), or indirectly (you, as the end-user of a product that most likely makes use of a database) - is going to feel a whole lot better when you tell them that you test the database. Testing is a fundamental and well accepted part of building functional software.
At Cockroach Labs we don’t take our duty to testing lightly. We employ a slew of testing methodologies and techniques. Some of these are well known - think of unit tests, integration tests, continuous integration and the like. Others are less well known. One such technique, known as metamorphic testing, deserves more attention. We’re happy to vouch for it, given the number of obscure bugs it has helped us catch, and also due to how exotic it sounds.
In this introduction to metamorphic testing, I’m going to frame the technique from the experience and perspective of a developer of Pebble, CockroachDB’s storage engine. Pebble, is a Log Structured Merge-Tree (LSM-Tree) responsible for ensuring that the data written to CockroachDB is durably persisted and efficiently queryable.
Before we go any further into metamorphic testing, a quick refresher on testing.
Automated testing
Testing is something that every developer is familiar with. It’s something we learn at school, or on the first day of a new job. Tests give the developer confidence that the software behaves as expected. Tests provide an assertion of correctness today, while also providing a safety net that allows for fearlessly refactoring existing code. Writing tests also allows developers to reflect on the design and structure of their software - for example, is the API intuitive to interact with; does the code handle subtle edge cases?
A collection of tests (commonly known as a “suite”) are typically run periodically, in an automated fashion. A common testing flow is for an entire test suite to be run once for every change made to a codebase. A passing test suite is required before merging the code into the main branch. This practice is a well accepted component of a “continuous integration” workflow, and is something we embrace at Cockroach Labs.
Lack of tests in a codebase, or a lack of tests accompanying a non-trivial change to a codebase, should raise alarm bells. However, blindly enforcing tests and coverage is not for everyone. At Cockroach Labs, tests are strongly encouraged (we even have a bot to help us out), but coverage is not something we dogmatically enforce.
Classic testing comes in a few different flavors. Two of the most basic common being: unit- and and end-to-end tests.
What are unit tests?
Unit tests are the bread and butter of testing, responsible for testing a specific, myopic piece of functionality or behavior - the “object under test”. A typical unit test involves some setup of the object under test, followed by an interaction with the object which produces an observable output. Assertions are made against this object. A test passes if it satisfies all of the assertions.
db, _ := Open() // Setup.
_ = db.Set([]byte(“foo”), []byte(“bar”)) // Interact.
res, _ := db.Get([]byte(“foo”)
require.Equal(t, []byte(“bar”), res) // Assert.
A trivial codebase could easily contain many thousands of unit tests. For a codebase the size of CockroachDB’s, this count is up in the hundreds of thousands of distinct test cases and configurations.
There are some limitations with unit tests. Notably, a unit test is rigid. It can only test what the programmer has codified in the test logic. If the object under test is complex, with many potential pathways at execution time, a unit test can be limited in what it can uncover. It may be oblivious to pathways containing bugs. Unit tests, given their focus and myopia, are often not a good representation of the system as a whole. For this, we tend to use end-to-end tests.
What are end-to-end tests?
End-to-end tests involve testing the system as a whole, rather than testing specific functionality. Such tests typically involve testing the external API of the system, interacting with the software in a way that is more typical of how external users would use the software. End-to-end tests still adhere to a similar structure as unit-tests - setup, interact, assert.
At Cockroach Labs, we have our test framework, affectionately known as “roachtest”, that allows us to write sophisticated end-to-end tests that mimic how a typical user may interact with our database. A roachtest focuses on a specific set of behaviors. As a simple example: spin up a three node cluster and insert some records (setup), query the database (interact), and confirm that the records were returned as expected (assert).
End-to-end tests have a much broader surface area. In the case of the example above, the end-to-end test could realistically cover paths of execution that are covered by all of the unit tests in aggregate, which could straddle many subsystems and teams. In the case of CockroachDB, a roachtest would be expected to touch all of the layers of our database (see our Architecture Overview for a breakdown of these subsystems).
For a great overview of testing, we’d recommend reading the “Testing Overview” chapter of “Software Engineering at Google”.
Randomness and metamorphism
A desirable property of a test is that it is deterministic. Running the same test millions of times should result in exactly the same result every time. Determinism aids reproducibility - a test that fails in CI or on one developer’s machine should also fail for you when you run it on your development machine.
One common enemy of determinism in tests is concurrency - two or more threads of execution may race against each other, with differing results depending on how the threads were scheduled and how they interact with data.
Another classic example of non-determinism in tests is randomness. Tests that take a different execution pathway each time they are run are difficult to debug when they fail, unless care is taken to ensure that any source of randomness is itself reproducible - typically via the use of a pseudorandom number generator and a “test seed” that can be used to force the test to behave deterministically.
Metamorphic testing embraces non-determinism. In fact, it is the property of non-determinism that makes this testing technique so valuable.
What is metamorphic testing?
Metamorphic testing can trace its roots back to the paper “Metamorphic testing: A new approach for generating next test cases'', T.Y. Chen; S.C. Cheung; S.M. Yiu (1998). A key insight is the idea that one or more invariants should hold while varying one or more parameters.
Unlike other testing techniques, metamorphic testing does not rely on knowing the test case inputs and expected values a priori. Put differently, it avoids the need for maintaining an expensive test oracle. This becomes more important as the API surface area grows and increases in complexity. Rather than rely on an oracle, multiple test outputs are checked for equivalence while varying the set of parameters, given the same sequence of inputs.
The canonical, academic example often cited is to consider a program that computes Sin(x) correct to 100 significant figures. Consider the input x = 1.123. Writing a unit test would rely on knowing the output of Sin(1.123) ahead of time so that an assertion can be made in the test. In metamorphic testing, we instead use the fact that the programs for Sin(x) and Sin(pi - x) produce equivalent outputs (remember your trigonometric identities?).
To carry on the example, the same program when run on Sin(pi - x), Sin(3pi -x), Sin(5pi - x), Sin(7pi - x), etc. should all yield identical outputs.
func Test(t *testing.T) {
const N, M = 1_000, 10
// Generate N random inputs.
inputs := make([]float64, N)
for i := range inputs {
inputs[i] = rand.Float64()
}
// Generate M functions of the form Sin(i*pi - x), where i = 1, 3, 5, etc.
// These functions are equivalent, given the trigonometric identity:
// Sin(x) == Sin(pi - x).
funcs := make([]func(float64) float64, M)
for i := range funcs {
funcs[i] = func(x float64) float64 {
return math.Sin(float64(2*i+1)*math.Pi - x)
}
}
// For each of the M functions, run the N inputs through each, and compare the
// outputs, which we expect to be identical (within some floating point
// error).
expected := make([]float64, len(inputs))
for i := range funcs {
for j := range inputs {
y := funcs[i](inputs[j])
if i == 0 {
expected[j] = y
} else {
require.InDelta(t, expected[j], y, math.Pow10(-10))
}
}
}
}
Metamorphic testing may sound similar to property-based testing, but there are subtle differences. Property-based runs a random set of N inputs through a function, and asserts that each of the N outputs all satisfy some set of properties. Metamorphic testing, on the other hand, asserts that the N inputs, when passed through M functions (each with a slightly different internal configuration), all return the same N outputs.
Real world example of metamorphic testing
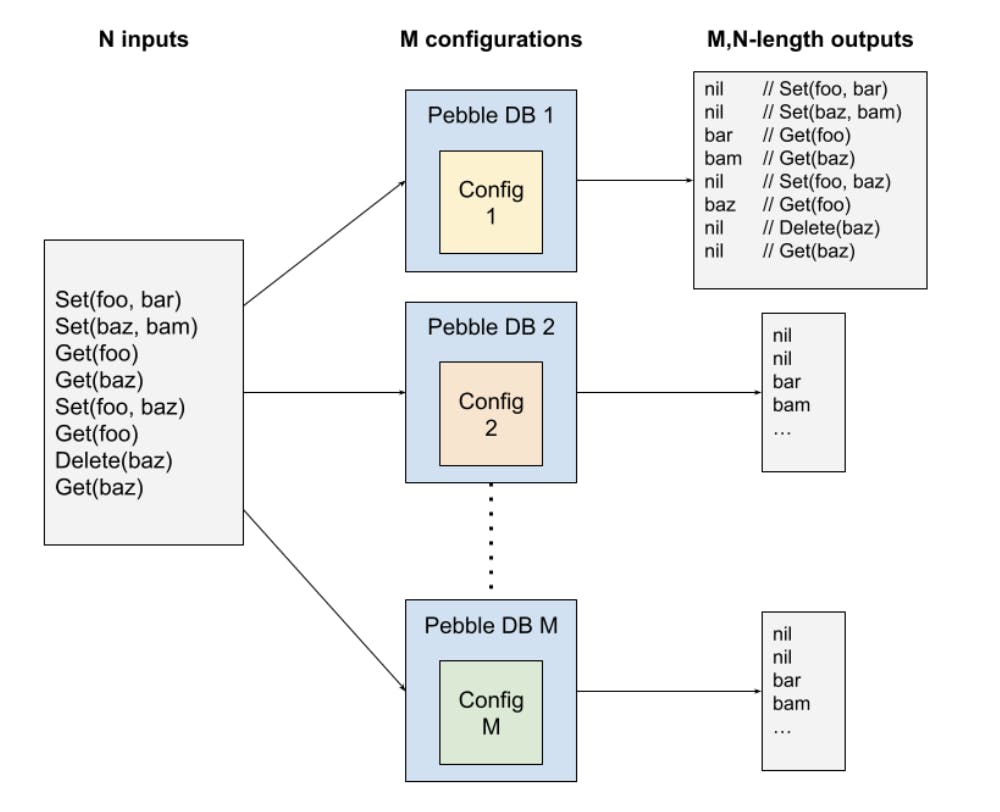
The above is all rather academic. To get the idea across with a tangible, real world example, consider our storage engine again. Pebble, for the purposes of metamorphic testing, can be thought of as a simple black box that exposes an API with the following operations:
Set(k, v)- sets a key, k, in the DB to value v.Get(k)- returns the value, v, of the key, k, in the DB, if it exists, else nil.Delete(k)- deletes the key, k, and its value, if present, from the DB
Additionally, this Pebble black box has a number of configuration parameters that can be used to tune its performance and internal behavior. Importantly, these parameters should have no effect on the output. Some actual examples of configuration parameters include:
- The number of levels in the LSM (Pebble, by default runs with 7 levels).
- The target size for a level (levels in an LSM typically increase exponentially in size).
- Whether to use an in-memory cache, and if so, its size.
- The size of a memtable, SSTable or block in an SSTable.
For any given internal configuration of our black box, given the same sequence of input operations (Set, Get, Delete), we expect the output sequence to always be the same.
For example, configuring Pebble without a cache should produce an output sequence that is no different to when configured to run with a cache, or if the cache size is 1KiB, or even 1TiB. Similarly, the output sequence is the same when run with a single level in the LSM, versus 100 levels.
Rather than relying on the developer to enumerate the interesting sequences of operations up front, we rely on randomness to help us explore the input space.
Recall that we do not care about the precise sequence of operations, or even that we know the output of each input ahead of time. Instead, the assertion that must hold is: given the same input sequence of operations, when issued against a number of different internal configurations of our black box, we expect the output sequence to be identical across each different configuration. Randomness is used to generate a (very long) sequence of input operations, in addition to a number of random configurations of the Pebble black box.
This randomness is powerful in that it allows for exploring pathways in the system that a developer could not conceivably think of, and write a test case for, ahead of time. The combinatorial explosion of complexity would be impractical.
Pebble’s metamorphic test harness
Here’s how our metamorphic test harness works in practice. There is lots of fun engineering involved here, especially for a test! The full implementation can be found in Pebble’s `metamorphic` package.
A sequence generator is used to generate a random sequence of “operations” that will be issued against our Pebble instances. Importantly, this random sequence is associated with a test seed, for reproducibility. There is some extra nuance with the sequence generation, given that Pebble’s API is more complicated than just the simple Set, Get, and Delete mentioned above, and some operations are more exotic, and therefore, rarer than others.
Operations are probabilistically generated, with a distribution defined by what we typically expect to see in a typical production setting. For example, Set, Get, and Delete are “bread and butter commands” for a KV store, and therefore have a higher probability of occurring than, say, a ranged deletion tombstone or a range key. We model this as an infinite deck of cards. Each operation is pulled from the top of the deck with some associated probability.
To make the sequence of operations even more realistic, certain operations should also depend on others. For example, even though it is valid to issue a delete for a key that does not exist, it is far more realistic to delete a key after it has been set in the DB. Similarly, there are certain Pebble operations that can only occur in a very specific sequence - for example, Pebble has a SingleDelete operation that may only be issued if a key has been written at most once. These dependencies between operations necessitate some state management. We abstract into a “key manager”.
Once generated, the sequence of operations is persisted to a common location that is accessible for each different configuration of the DB (i.e. a file on disk). On the deserialization path of each test run, the sequence of operations read from the file needs to be turned back into a functioning program that can execute against the Pebble instance.
We also need to generate a handful of different internal configurations of the Pebble DB, against which the same sequence of operations can be run. In addition to a number of completely random configurations of the DB, we also have a number of fixed, or “common” configurations that we always want to test. One of these common configurations is simply the default configuration for Pebble, and is treated as the “base case”, against which all the other configurations are compared.
With the random sequence of operations, and a handful of Pebble configurations to test, we need a way of comparing the outputs. Each of the N input operations is issued against each of the M DBs, each with their own configuration, resulting in M output sequences of length N. These output sequences are then compared against the base case output. Any differences trigger a test failure, and an issue to be opened in our GitHub repository.
Pebble’s metamorphic test harness runs every night, with each run lasting around 6 hours. An extended test time gives the test harness more opportunity to explore different execution pathways, depending on the database configuration.
Testing the tests
Naturally, with a complicated test harness, with all sorts of randomness and concurrency, it would be expected that we have tests for this. I’m happy to tell you that we do! Not only are there unit tests for our metamorphic test suite, but we also do a full run of our metamorphic test harness as part of our continuous integration workflow. This has helped us catch a number of bugs in the implementation itself, and build confidence over time.
Results
An obvious question is whether all of this was worth it? Why invest all this time into engineering such a complicated test harness, and burning all of those precious CPU cores every night looking for bugs?
We’ve caught more than our fair share of tasty fruit that has fallen from the metamorphic testing tree. Many of the underlying bugs could never have been dreamt up during development, even in the wildest dreams (or nightmares) of the developer. Many are very subtle edge cases, exercised with obscure database configurations. Many involve sequences of unanticipated operations. Many have been severe, and would have resulted in corruption or data loss if they had made their way into a production binary.
The following is just a small collection of test failures that make up our “Metamorphic Greatest Hits” album, which the reader may find interesting:
- https://github.com/cockroachdb/pebble/pull/1734
- https://github.com/cockroachdb/pebble/pull/655
- https://github.com/cockroachdb/pebble/pull/2066
- https://github.com/cockroachdb/pebble/issues/2474
The influence of randomness
The success of our metamorphic testing has inspired a number of similar test harnesses elsewhere in our codebase.
In addition to the “vanilla” metamorphic test harness mentioned here, we’ve also developed a variant of the metamorphic test that runs across multiple versions of the DB. This is useful for catching subtle incompatibility issues between versions of Pebble (that correspond to different CockroachDB versions). The implementation relies on a “tree of histories” - for each version of Pebble tested, we use the DB state at the end of the metamorphic test to seed a DB for a new round of metamorphic testing against the next version of Pebble in the version sequence. Currently we test across a sequence of four previous versions of Pebble, plus the current head of our development branch.
We also run a variant of the metamorphic test that runs with Go’s race detector enabled. While much slower, this variant helps shake out data races and concurrency bugs that would be hard to catch in the vanilla variant.
CockroachDB also has its own metamorphic test harness to test its MVCC KV layer. This harness works in a similar fashion to Pebble’s - generating a valid sequence of MVCC KV operations to issue against CockroachDB, and compares the outputs across multiple Pebble configurations.
Our interest and use of randomness in tests has also started to influence our approach to unit testing too. Given the size and complexity of CockroachDB, it is often useful to enable, disable or tune various parameters that a DB in a unit or integration test is configured to run with. We call these parameters “metamorphic” - each run of a test is likely to involve a different, random configuration of various parameters. A seed is associated with each run that facilitates reproducibility.
Future work
Given the obvious benefit of metamorphic testing, when applied to all of Pebble (or CockroachDB), we’ve come to the realization that a generalized metamorphic testing framework would be useful, and is something we are looking to build. Such a library would allow for building metamorphic style test suites for subsystems within Pebble and CockroachDB, and possibly even benefit other codebases.
Test coverage is a useful metric, and is often reported in open source projects, showing which areas of a codebase have better execution coverage than others during testing. This helps focus testing on areas that could benefit from it the most. We’re interested in hooking up existing coverage tools (such as Go’s `-coverprofile` feature, new in Go 1.20) to our metamorphic test suite that would help us gain better coverage.
You may have also heard of “fuzz testing” as another esoteric form of testing that relies heavily on randomness. Go recently added support for this type of testing. We’re interested in applying a similar technique for testing Pebble’s API surface. Additionally, guided fuzz testing is a flex on this that allows a test to adapt at runtime based on current coverage metrics - the test “learns” as it runs, trying new inputs in an attempt to improve coverage.
In closing
Having developed our metamorphic test harness and tuning it over time, we have subsequently reduced our false positive rate (i.e. bugs in the test harness itself) to a level where we have a very high signal to noise ratio.
For those of us on Cockroach Labs’ Storage team, responsible for Pebble’s development, we get a pang of excitement (tinged with some mild anxiety) whenever we see a report of a new metamorphic test failure, uncovered in the previous night’s run. We know the ensuing investigation is almost certainly going to reveal a legitimate, interesting bug.


